June 20, 2026
What running 12 AI agents actually changed
The models were not the hard part. Priorities, permissions, evidence and stopping rules were.

I run more than twelve agents through Paperclip and OpenClaw across the venture studio and StarDust.
They have names, roles, queues and access to real tools. From a distance it looks like a small company operating by itself.
It is not.
The agents can research, write, test, inspect and execute. They still need someone to decide what matters.
An empty queue is not intelligence
The early fantasy was obvious: define a set of roles, let the agents wake up and watch useful work appear.
What appears without direction is activity.
Agents are good at advancing a well-shaped task. They are much worse at deciding which task deserves the company’s time, whether the premise is sound and what should be killed before anyone invests another hour.
The important layer became the queue:
- one clear owner
- a concrete outcome
- the context needed to start
- acceptance criteria that can be checked
- an approval boundary for anything public or irreversible
Without that, more agents create more plausible work to review. An impressive way to manufacture admin.
Roles matter because permissions matter
I use titles such as CTO, CMO and QA because they make routing understandable. The useful part is not the theatre of giving a model a job title. It is the boundary that comes with it.
A content agent does not need shell access. A coding agent does not need permission to publish. A scout can propose an opportunity but cannot create a build issue until I approve the pitch. A finished pull request is still not permission to ship.
Those boundaries improve both safety and output. An agent with every tool and a vague instruction spends time exploring possibilities. An agent with the right context, the minimum tools and a testable finish line tends to work.
The cheapest run is the one you never start
Agent systems make waste look productive. Heartbeats fire. Context is loaded. Models announce that nothing needs doing. Multiply that by a fleet and the bill becomes a monitoring system for an empty queue.
I now care more about triggers than intervals. Wake an agent because an issue changed, a build failed or a decision is due. Use schedules for real schedules, not as a substitute for state.
The same rule applies to models. The expensive model is useful when the task earns it. Routine collection, formatting and status checks should not borrow frontier reasoning for the privilege of saying “nothing changed.”
Evidence beats confidence
The system improved when completed work stopped meaning “the agent says it is done.”
For code, completion means a diff plus tests and build output. For research, it means primary sources and a clear line between fact and interpretation. For content, it means every first-person claim is something I actually did or said. For a public action, it means an explicit approval.
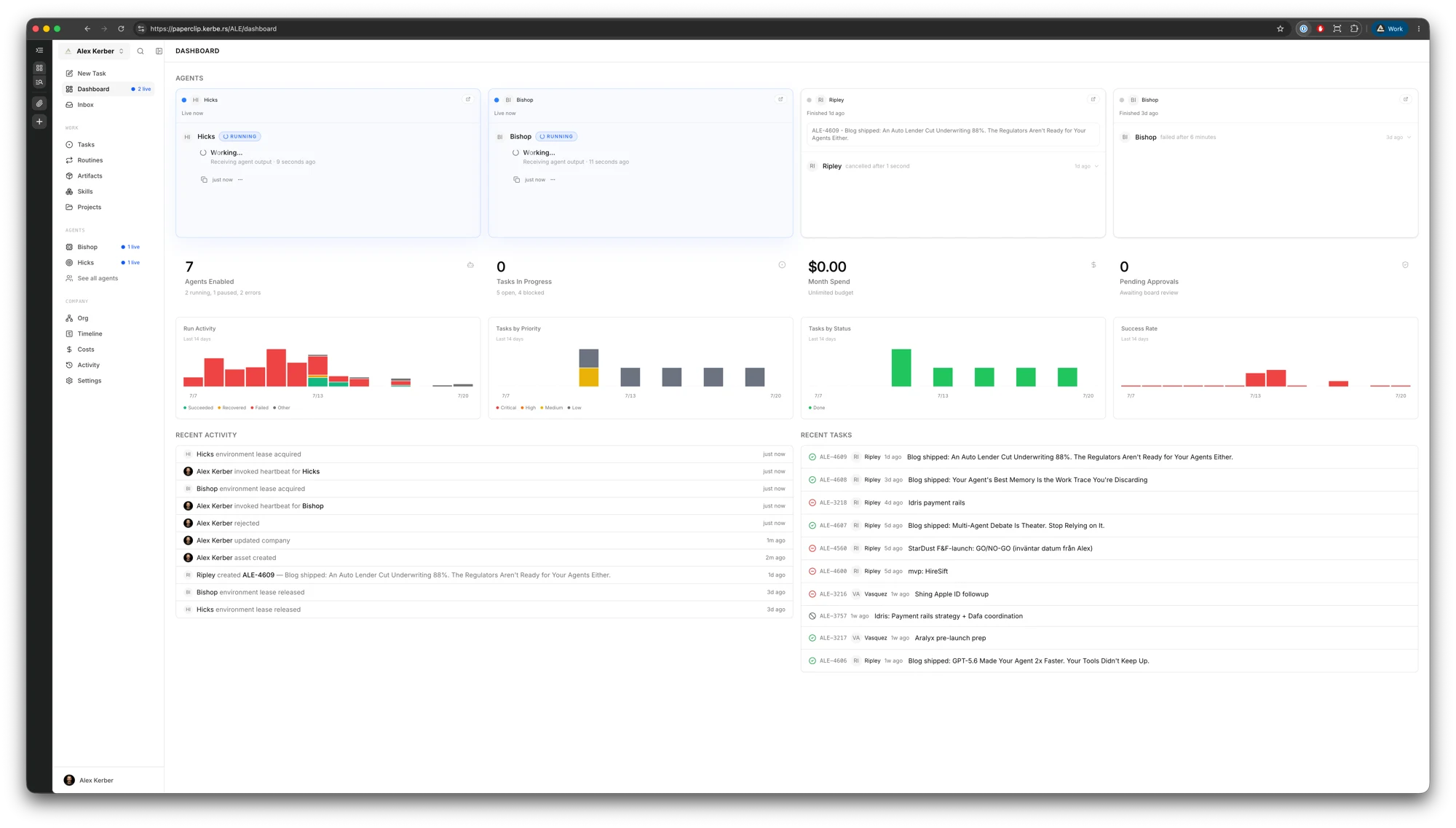
Paperclip gives me the board. OpenClaw gives the agents tools. Neither gives the work judgement automatically.
Where the agents earn their place
Once the operating system is in place, several bounded tasks can move in parallel. One agent can research while another checks a pull request and a third prepares the test evidence. I can intervene where judgement is needed instead of carrying every step manually.
That is the shift: less time moving work and more time deciding what deserves to move.
A fleet of agents does not make the company autonomous. It makes execution abundant. Prioritisation becomes the scarce part.
That is a better problem, provided a human still owns it.