April 2, 2026
What 100K GitHub Stars Can and Cannot Tell Us About AI Coding
Claw Code crossed 100,000 GitHub stars in a day. The record claim matters less than the engineering underneath it: verification loops, small skills and disciplined context.

Two days ago I wrote about Claude Code’s source leaking via npm. The leaked code was archived and forked, and a reimplementation appeared at ultraworkers/claw-code. It crossed 100,000 stars in under 24 hours. The repo called that the fastest such run in GitHub history. GitHub does not certify records like this, so I would treat the label as the project’s claim. I did watch it gain roughly a thousand stars every ten minutes during a livestream.
The incident, the tooling and the hype keep getting blended together. Separating them makes the useful engineering much easier to see.
The event
Anthropic confirmed that a packaging error caused the source exposure. Source maps shipped in the npm bundle and pointed to an unprotected R2 bucket. Half a million lines of TypeScript, no model weights, no customer data. I covered the details in the previous post.
The reimplementation was led by two Korean developers, Sigrid and Bellman. Their public posts describe using their own agent tooling, oh-my-codex and oh-my-claudecode, to scaffold a Rust workspace and Python port in a matter of hours.
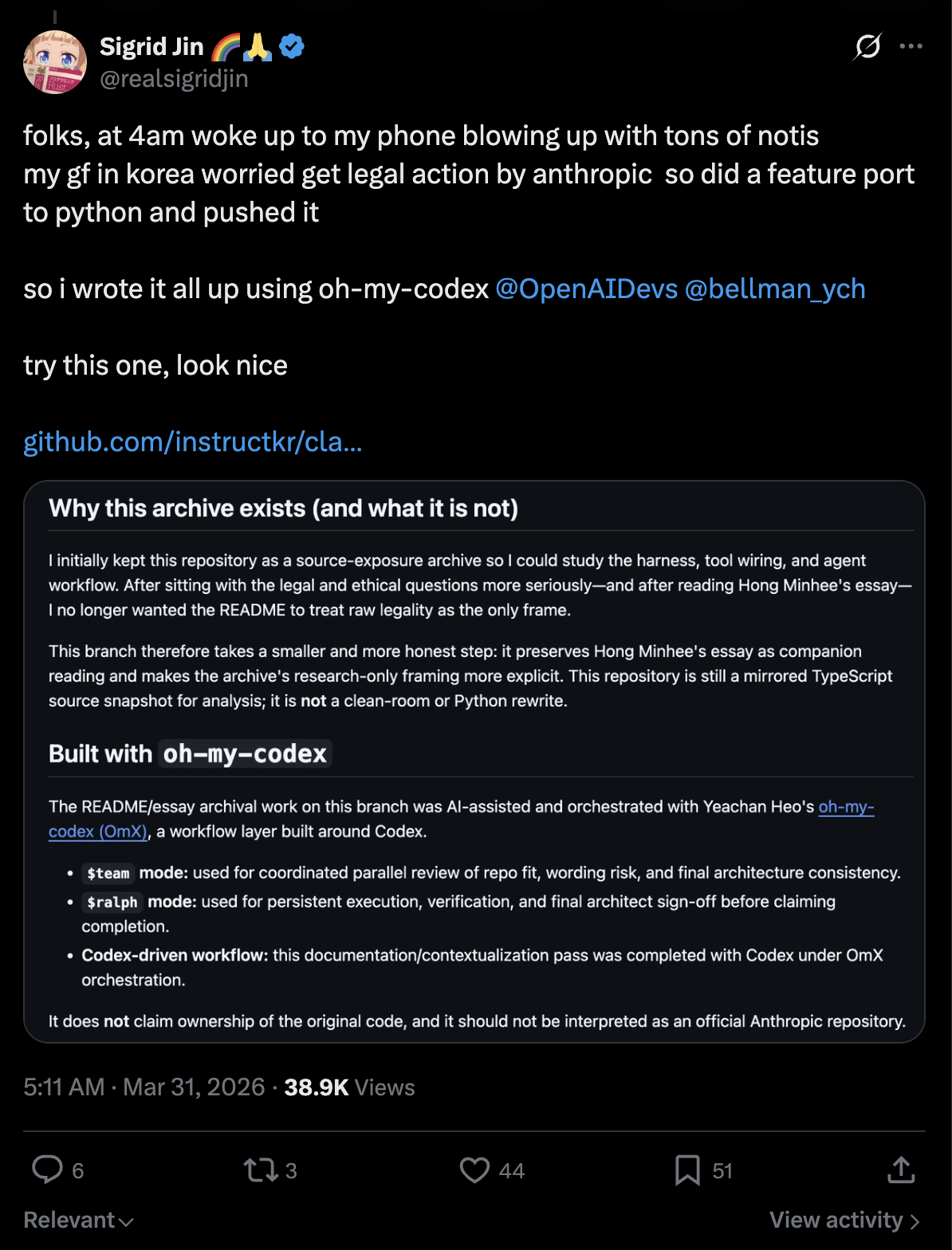
The repo describes itself as a clean-room reimplementation that “does not claim ownership of the original code” and states it is not affiliated with Anthropic. Anthropic reportedly issued takedowns against copies of the leaked source. Clean-room reimplementation is a more defensible position than hosting leaked code directly. The whole area remains legally and technically contested.
The hype
The star count rode six waves simultaneously: a spectacular leak, a clean-room narrative, an anti-big-tech angle, livestreams, X posts and a “history in real time” framing. The project has substance, but its star count is a very noisy measure of product maturity.
The unusually fast growth in stars and forks says as much about social distribution and mirroring as it does about adoption.
GitHub stars in 2026 don’t measure what they used to. In the AI scene a star also measures narrative, timing, memetics, conflict and social distribution. This repo scored on all of them at once.
Claims about two billion tokens per day, coding from an airplane by text message and five simultaneous Codex Pro subscriptions are self-reported. They make good social posts. I would not use them as engineering evidence.
The substance
The implementation has three design choices I want to keep, regardless of the star count.
1. Verification loops over single-shot prompts
The “Ralph” pattern keeps implementation, verification and repair in a persistent loop. Most people prompt, review, fix manually and prompt again. Ralph automates that cycle. The agent does not stop until the task passes verification.
CI/CD has used this pattern for years. Moving it inside the agent’s execution loop changes the interaction: the agent brings back a verified result instead of stopping after its first plausible patch.
2. Small and composable skills
Bellman keeps skill files under 50-70 lines. His take: “Most skills are entirely slop.” A skill is a pointer with intent. The intelligence comes from the agent and the orchestration, not from stuffing a prompt with instructions.
This is the opposite of the “superprompt” approach. Instead of one massive system prompt trying to cover everything, you have small modular skills that chain together. The harness decides which skills to inject based on the task. Context stays lean.
3. Context discipline through pointers
Everything is a file reference. Skills point to other skills and files. Agents reference paths instead of holding the full context, which reduces the bloat that kills long-running sessions.
The idea is basic computer science, applied to a problem many teams still solve by cramming everything into one prompt.
The tools
Three repos implement these patterns. Each one solves a different layer.
oh-my-claudecode (OMC)
oh-my-claudecode is a multi-agent orchestration plugin for Claude Code. Its README documents specialized agents, skills and MCP-powered tools; those counts move too quickly to make useful prose.
It runs a staged pipeline across coordinated Claude agents in tmux panes: plan, PRD, execute, verify and repair. Model routing delegates simpler tasks to Haiku and complex reasoning to Opus. A built-in “AI slop cleaner” skill strips dead code and unnecessary abstractions.
oh-my-codex (OMX)
oh-my-codex applies the same approach to OpenAI’s Codex CLI. It wraps Codex sessions in tmux with custom HUDs, teammate panes and agent teams. The project says its tooling was used to build Claw Code.
ClawHip
Daemon-first notification router written in Rust. Monitors Git commits, GitHub issues, tmux sessions and custom events. Routes notifications to Discord and Slack through a typed event pipeline. The key design choice: it bypasses gateway sessions to avoid polluting agent context with notification noise. Your routing stays separate from your agent’s reasoning.
What actually matters here
The model still matters, but the harness now explains a larger share of the result. oh-my-claudecode describes a team pipeline with planning, execution, verification and repair. oh-my-codex builds similar machinery around Codex with hooks, agent teams and visible session state.
Models are not commodities yet: capability, latency and access still vary. But many developers can rent the same frontier models. Workflow design is one of the few parts they fully control.
The star record will age quickly. The useful parts are less glamorous: plan → execute → verify → fix, small skills, file pointers instead of prompt novels, and a notification path that does not poison the agent’s working context.